Vidu Q3: Built for Storytelling
The world's first native 16-second audio-video generation model, featuring precise shot transitions, multi-shot cinematic storytelling, and support for content generation in Chinese, English, and Japanese. With more accurate text rendering, professional-grade camera control, and greater consistency across scenes, Vidu Q3 empowers creators to produce animations, short-form series, and film & TV content with ease.
Industry-Leading Performance
A Top-Ranked Video Generation Model
Vidu Q3 achieved top-tier results across leading international benchmarks, including a No. 1 ranking on Artificial Analysis at the time of its release. These results highlighted its outstanding quality, consistency, and controllability in AI video generation.
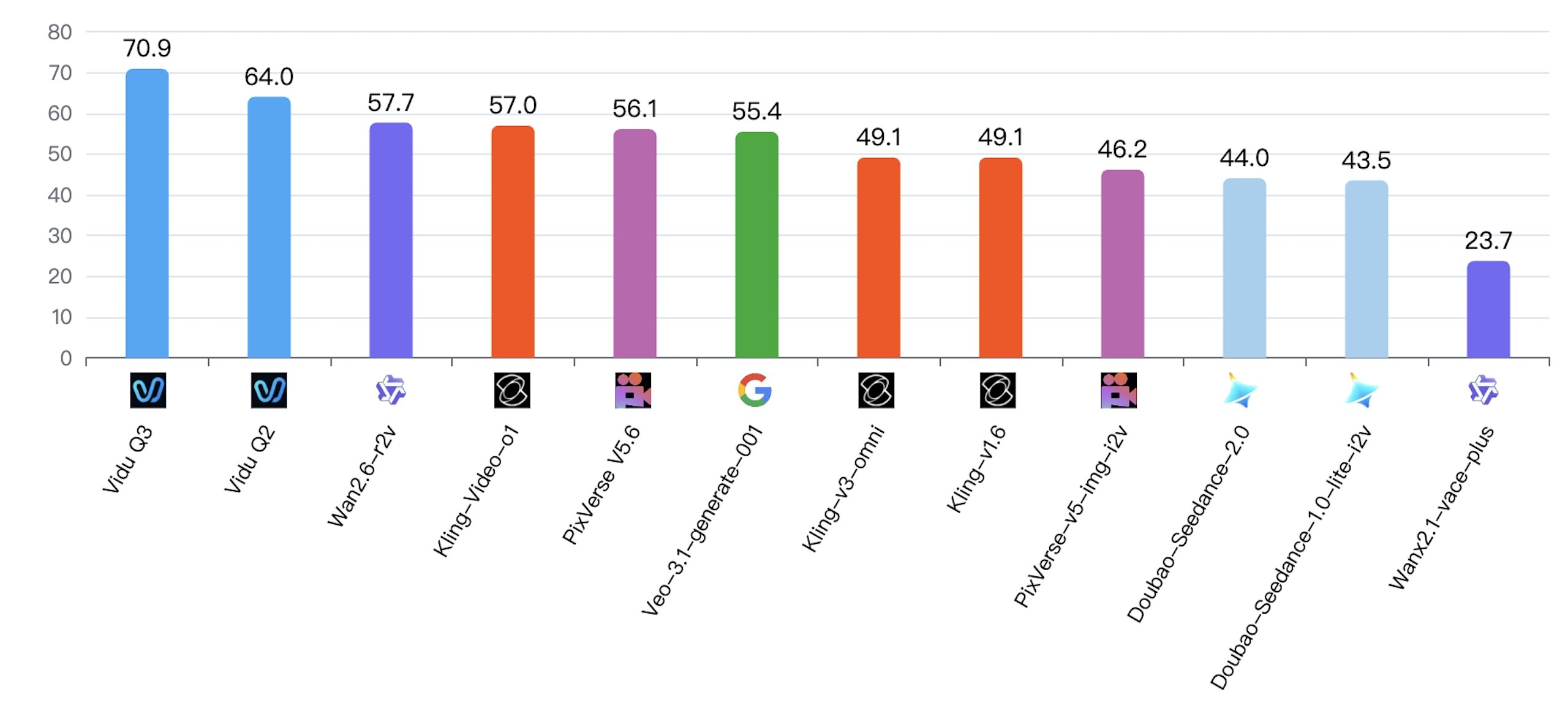
No. 1 on the World's First Reference-to-Video Benchmark
Vidu Q3 achieved the top ranking on SuperCLUE-R2V, the world's first benchmark for evaluating reference-to-video models. The benchmark measures performance in character fidelity, subject consistency, visual quality, motion realism, and real-world creative applications.
Character Fidelity
Vidu Q3 achieved the highest overall score in the multi-image reference category with 70.89 points, and ranked No. 1 in the single-image reference character fidelity category with 72.43 points.
Subject Consistency
Vidu Q3 and Vidu Q2 both achieved a perfect score of 100, demonstrating exceptional consistency in preserving subject identity across generated videos.
Real-World Application Performance
Vidu Q3 secured the top position with 70.80 points, highlighting its strong commercial readiness and ability to support professional content production across industries.
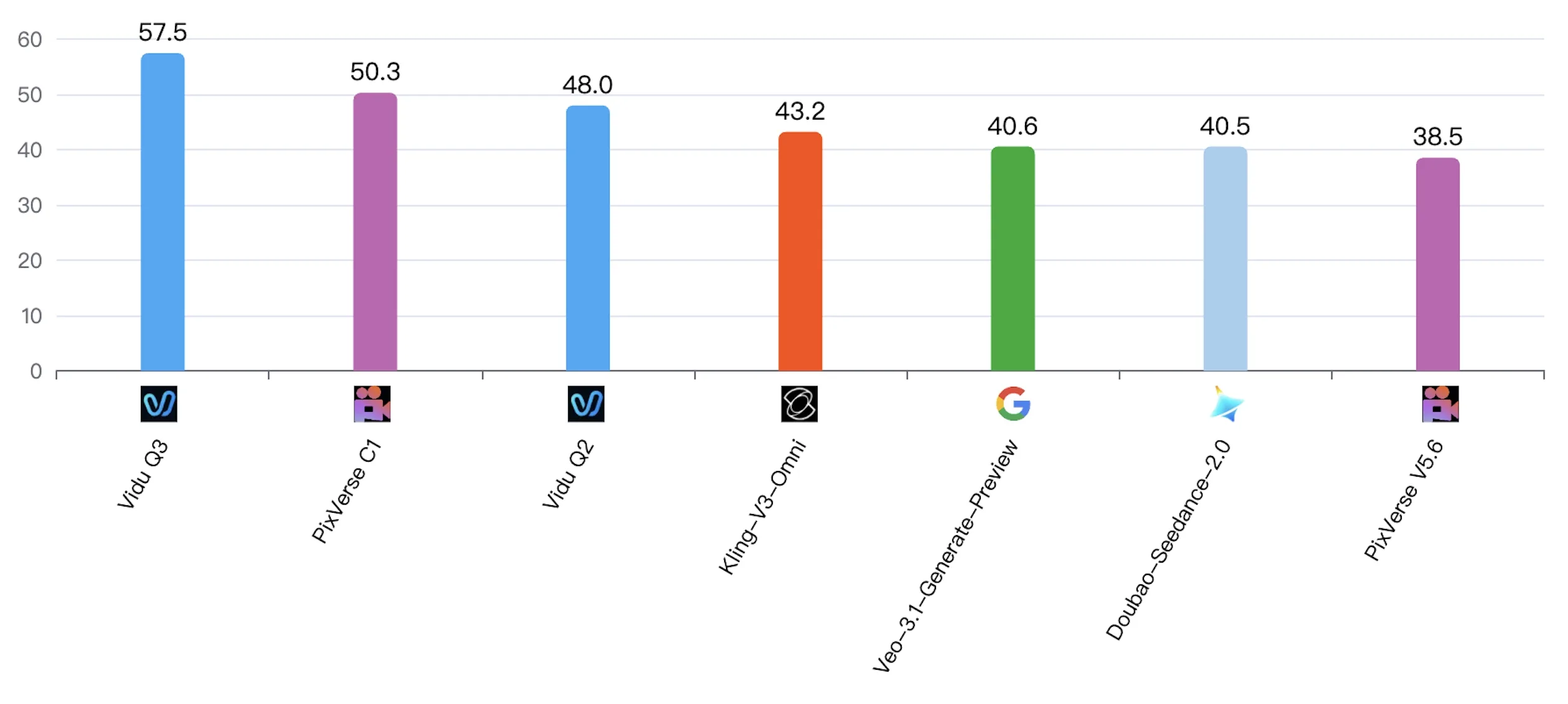
No. 1 on the World's First AI Comic Drama Benchmark
Vidu Q3 achieved leading results on the world's first benchmark for AI Comic Drama creation. Powered by advanced text-to-video, image-to-video, and reference-to-video generation, it enables creators to produce richer stories with greater consistency, control, and visual expression.
Production-Ready Performance
Vidu Q3 delivers stronger instruction following and enhanced visual fidelity, enabling more nuanced and expressive character performances. Beyond native audio-video generation, it achieves cinematic-quality multi-character dialogue, with synchronized speech, natural interactions, and more compelling storytelling.
Vidu Q3 supports precise shot transitions and advanced multi-shot storytelling. It can seamlessly adapt camera angles and visual language to the flow of a narrative, enabling complex scene changes and transitions within a single generation. Each shot is carefully aligned with the pacing and emotional beats of the story, creating a more immersive and visually compelling experience. Move beyond static viewpoints and tell every story with cinematic-quality storytelling.
Video and text are generated together in a single workflow, eliminating the need for time-consuming post-production editing. Vidu Q3 supports native text rendering in Chinese, English, and Japanese, allowing text to be seamlessly integrated into the scene with accurate positioning and natural perspective. No complex overlays, masking, or frame-by-frame tracking required.
Designed for professional content creation, Vidu Q3 supports a wide range of production scenarios, including comic dramas, short-form series, and film & TV content. With greater efficiency, consistency, and creative control, it enables teams to scale production faster than ever before—bringing AI video into the age of industrialized content creation.
Vidu Q3 further elevates reference-to-video generation, delivering stronger visual effects and more compelling scene creation. With improved consistency, detail, and cinematic expression, it enables creators to produce content that meets the standards of professional film and TV storytelling.
Vidu Q3 goes beyond video generation.
It is a next-generation audio-video engine designed to power the future of comic dramas, short-form series, advertising, and film & TV production.
Integration
Fast API Integration
Flexible model options designed to meet different creative and production needs.
Full Model Lineup
Enhanced Reference-to-Video Model
